Sharding-Sphere 사용 튜토리얼 - 1편

회사에서 야심차게 샤딩스피어를 쓰게 되었는데, 처음에 한국에 자료가 없어서 꽤나 난감했었다. 특히나 공식홈페이지대로 세팅해도 실행이 안되는 현상까지 있어서 삽질을 조금 했었다. (지금은 해결된 것 같지만..)
이런 사람이 더 있지 않을까 싶어 샤딩스피어 사용 튜토리얼로 안내한다!
1. 샤딩이란?
일단 샤딩스피어를 진행하기에 앞서 샤딩에 대해서 간단하게 이해하자!
한개의 DB에 많은 데이터가 쌓이다보면 용량도 커지지만, 데이터 처리 성능이 큰 영향을 받게 된다. 이러한 부분을 해결 하기 위해서 샤딩을 사용한다. 샤딩을 사용하면 DB 트래픽이 분산되어 큰 효과를 볼 수 있다. 여기서, 샤딩의 핵심은 데이터를 효율적으로 분산시키는 것이다.
분산이 잘 되지 않는다면 한쪽으로 Data 요청이 몰리게 되고, 결국 성능이 느려지게 된다. 샤드 키를 통해 데이터를 균일하게 분산시키는 것이 샤딩의 필수 조건이다.
샤딩의 종류

위 사진을 보다 싶이 크게 두가지로 나뉜다.
- 수직 분할 (좌측)
- 수평 분할 (우측)
보편적으로 대부분 수평 분할을 사용한다.
1. 수직 분할
한 스키마에 저장되어 있는 데이터를 특정 컬럼 단위로 잘라내어 분할 저장한다. 수직 파티셔닝은 각 스키마를 나누고 데이터가 따라 옮겨간다.
(ex) 한 고객은 좋아하는 색상을 하나씩 가지고 있다. 하지만 현재는 이 정보를 ‘User’ 라는 테이블에 다 갖고 있지만 ‘Color’ 라는 테이블로 색상 정보를 분할하는 것이다.
결국 논리적 엔티티들을 다른 물리 엔티티들로 나누는 것을 의미한다.
2. 수평 분할
한 스키마에 저장되어 있는 데이터를 특정 알고리즘을 통해 행 단위로 잘라내어 분할 저장한다. 수평 분할은 하나로 구성된 스키마를 동일한 구성의 여러개의 스키마로 분리한 후, 각 스키마에 어떤 데이터가 저장될 지를 샤드키를 기준으로 분리한다.
(ex) 고객 정보는 ‘User’ 테이블에 모두 가지고 있다. 하지만 1~2 유저는 ‘User1’ 테이블에, 3~4 유저는 ‘User2’ 테이블에 저장시켜 데이터를 분할한다.
보통 수평분할의 경우 하나의 데이터 베이스 안에서 이루어진다. (하지만 현재 본인은 여러개의 데이터 베이스로 진행하는 중..)
제일 보편적으로 많이 사용하고, 애플리케이션 서버 레벨에서 진행할 수도 있다. 또한 분할을 시키기 위한 샤딩 알고리즘을 필요로 한다.
샤딩 알고리즘
수평 분할을 통한 샤딩은 샤딩 알고리즘이 필요하다. 기준이 되는 샤드키를 통해 어느 스키마에 접근하여 데이터를 핸들링 할 것인지 정해야 하기 때문이다. 한마디로 라우팅을 위한 알고리즘이다.
크게 두가지 샤딩 방법이 있다.
- Modular Sharding
- Range Sharding
1. Modular Sharding
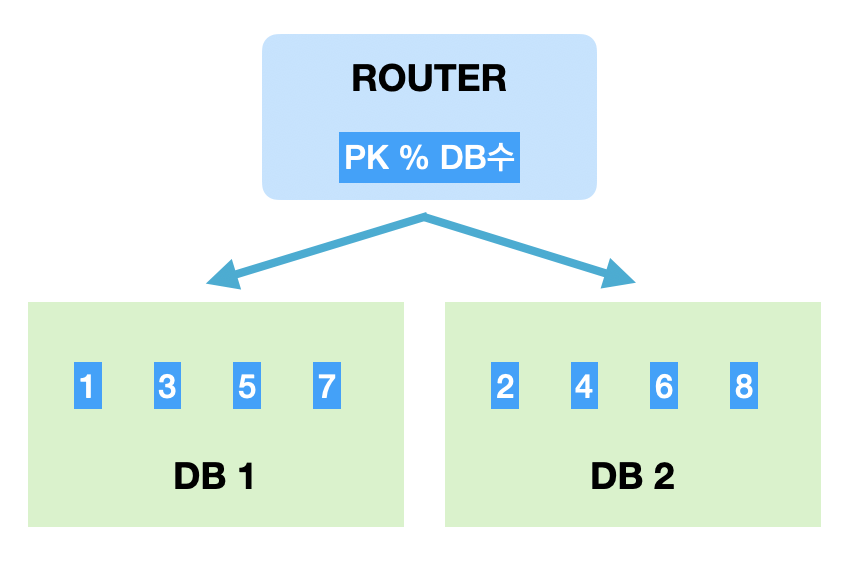
Modular 샤딩은 샤드키를 모듈러 연산한 결과로 DB를 선택하는 방식이다.
- 장점: Range 샤딩에 비해 데이터가 균일하게 분산된다.
- 단점: DB를 추가 증설하게 된다면 이미 적재된 데이터들의 재정렬이 필요하다.
- (ex) (DB는 2개, 상품번호가 0~10까지 있을 경우) 상품번호 % 2 모듈러 연산시 DB1에는 0,2,4,6,8,10 상품, DB2에는 1,3,5,7,9 상품이 들어가게 된다.
Modular 샤딩은 데이터량이 일정 수준에서 유지될 것으로 예상되는 데이터 성격을 가진 곳에 적용할 때 어울리는 방식이다.
실제적으로 현 회사에서 상품 데이터를 적재하고있으나, 해당 데이터는 장기적으로 미사용할 경우 다른 디비에 옮겨 보관하기 때문에 적합하다. 데이터가 꾸준히 늘어나더라도 적재속도가 그리 빠르지 않다면 문제없다고 한다.
일단 데이터가 균일하게 분산된다는 점 자체가 트래픽을 안전하게 소화하면서도 DB 리소스를 최대한 활용할 수 있기 때문이다.
2. Range Sharding
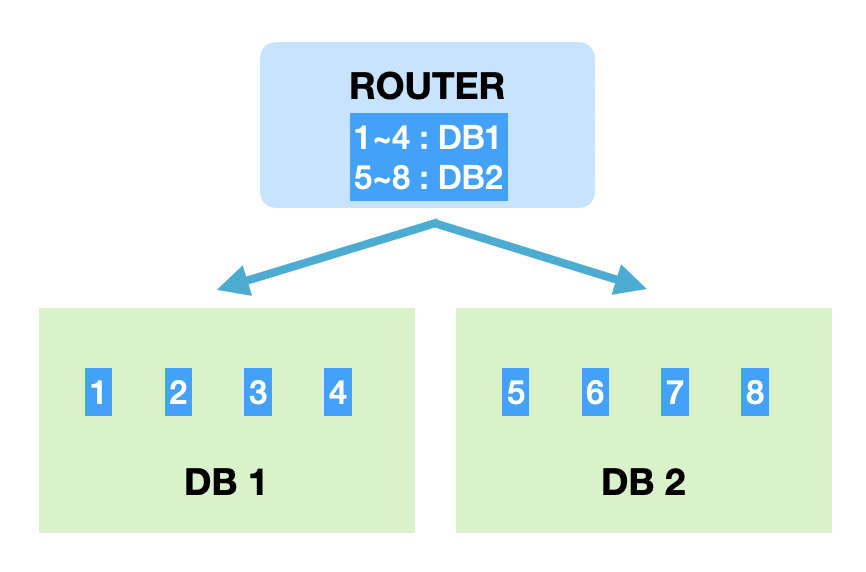
Range 샤딩은 샤드키의 범위를 기준으로 DB를 선택하는 방식이다.
- 장점: Modular 샤딩에 비해 증설에 재정렬 비용이 들지 않는다.
- 단점: 일부 DB에 데이터가 몰릴 수 있다.
Range 샤딩은 증설작업에 드는 비용이 크지 않다. Modular의 경우 증설작업이 진행될 경우 기존 데이터들도 모두 재정렬을 해야한다. 이런 부분에서 편하다.
하지만 많이 접근하는 데이터가 있는 DB쪽으로 트래픽이나 데이터량이 몰릴 수 있다. 결국 샤딩을 했더라도 동일한 현상이 나타난다면 또 부하 분산을 통해 DB를 쪼개 재정렬하는 작업이 필요하고, 반대로 트래픽이 저조한 DB는 통합 작업을 통해 유지비용을 아끼도록 관리해야한다.
그래서

샤딩은 데이터가 많을 경우 효율적으로 데이터를 나누어 부하를 줄일 수 있다.
하지만 운영 복잡도가 높아지기 때문에 최대한 샤딩을 피하여 개선할 수 있는 방법을 찾고 시도해 본 후 진행하는 것이 좋다.
샤딩 스피어

샤딩스피어는 이러한 샤딩을 어플리케이션단에서 편하게 제어할 수 있도록 하는 미들웨어와 비슷하다.
현재 Java 진영에서 사용되며 Spring에서도 손쉽게 사용할 수 있다. 자바뿐만 아니라 쿠버네티스단에서도 사용할 수 있도록 개발중인 것으로 보인다. 중국에서 만들어서 그런지 중국에서 특히나 많이 사용하고 있다. 그런 이유로 구글에서 검색하는 것보다 바이두에서 검색하는게 훨씬 더 많은 자료, 양질의 자료가 나온다. (중국어를 번역해야하는건 덤이다)
샤딩 스피어의 지원 종류
- Sharding-JDBC
- Sharding-Proxy
- Sharding-Sidecar
모두 분산 트랜잭션 및 분산 거버넌스 기능을 제공한다.
1. Sharding-JDBC
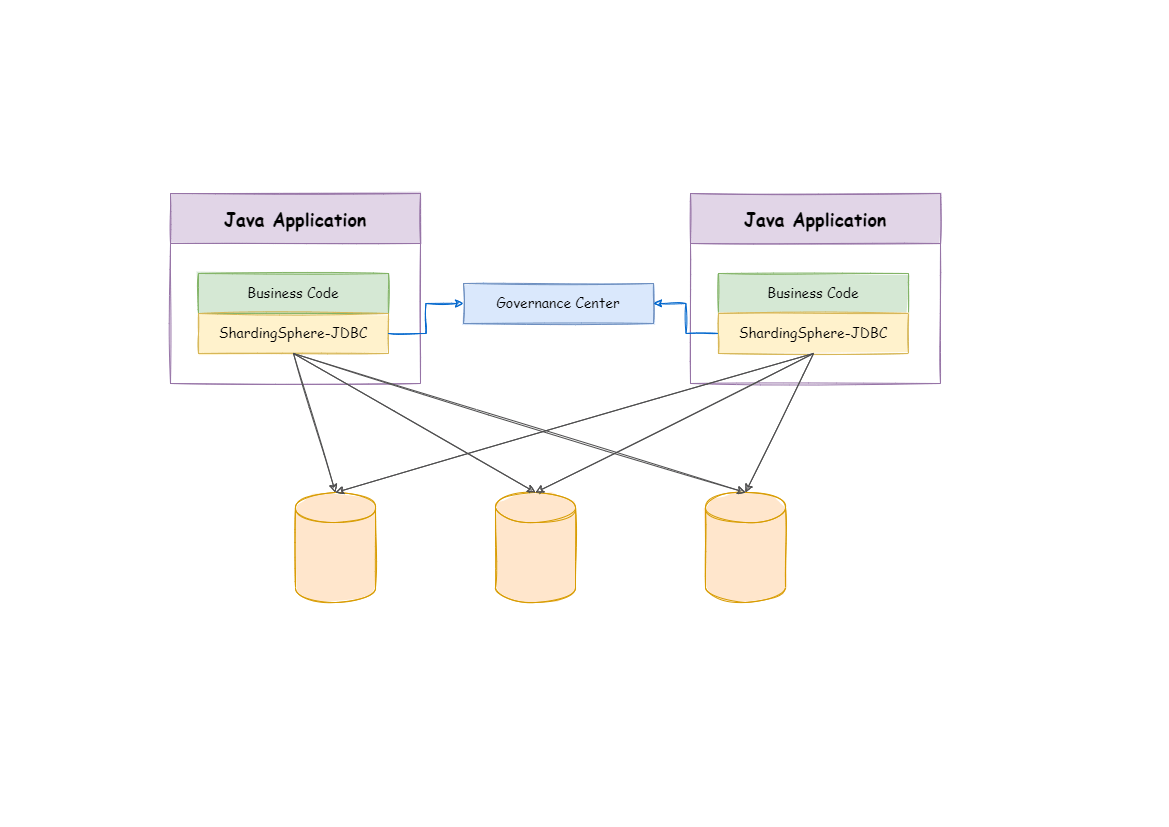
ShardingSphere-JDBC는 본인을 Java JDBC 계층에서 추가 서비스를 제공하는 자바 프레임워크로 정의한다.
애플리케이션단 <-> 샤딩스피어 <-> DB 로 연결되고, 모든 종류의 ORM 프레임워크와 완전히 호환된다. 즉, 샤딩스피어가 애플리케이션과 DB 사이에 끼어서 특정 샤딩 알고리즘을 통해 어떤 디비에 접근해야하는지 계산하여 DB에 접근시켜 데이터를 들고올수 있게 해주는 안내원 같은 친구라고 보면된다.
- JDBC 기반 ORM 프레임워크(JPA, Mybatis, Spring JDBC 등)에 적용가능
- DBCP, BoneCp, HikariCP 등의 서드파티 데이터베이스 접속 풀 지원
- 모든 종류의 JDBC 표준 데이터베이스 지원 (MySQL, PostgreSQL, Oracle 등)
2. Sharding-Proxy
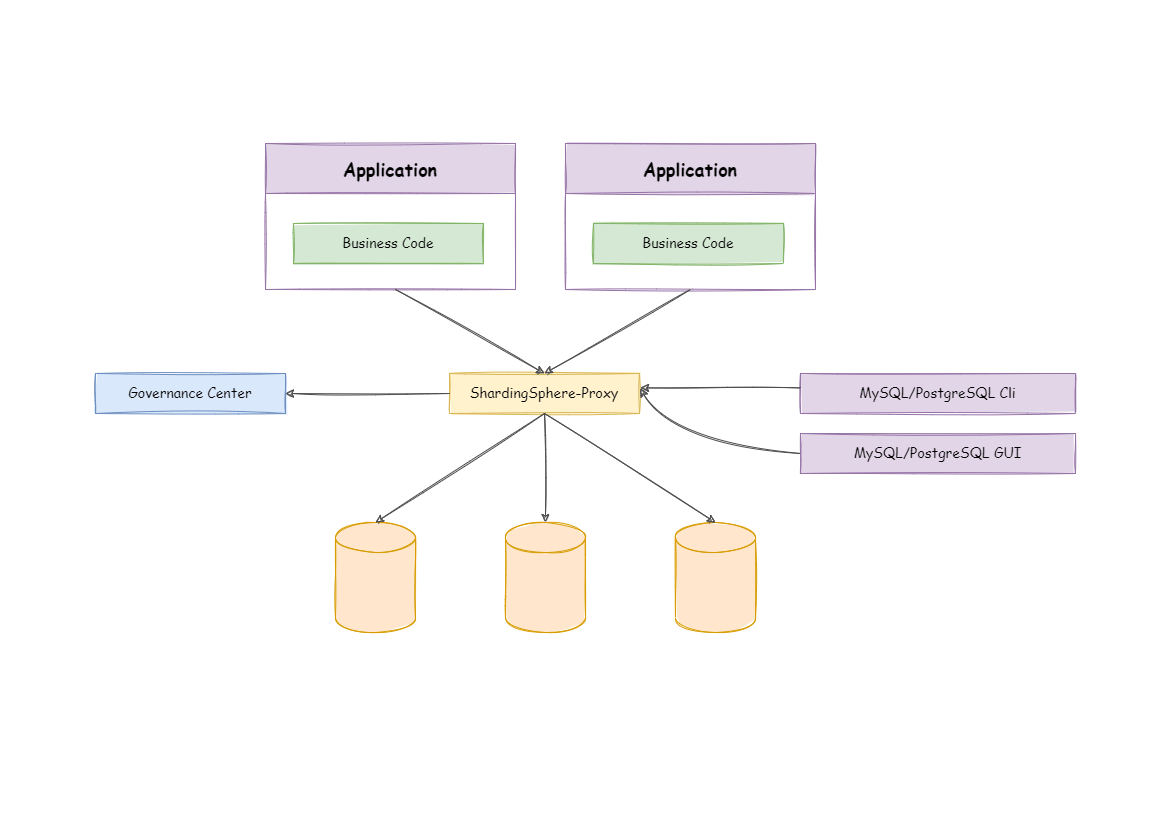
ShardingSphere-Proxy는 본인을 데이터베이스 프록시로 정의하여 데이터베이스 프로토콜을 캡슐화 하여 데이터베이스 서버를 제공한다.
하나의 서버처럼 동작하며 MySQL, PostgreSQL과 호환되는 모든 종류의 터미널을 사용할 수 있다. DBA가 편리하게 데이터 운영을 할 수 있는 SQL 프로토콜이다.
- MySQL 및 Postgre SQL 서버같이 직접 사용할 수 있다.
- MySQL, Postgre의 SQL 프로토콜이 호환되기 때문에 모든 종류의 터미널에 적용가능하다.
3. Sharding-Sidecar (예정)
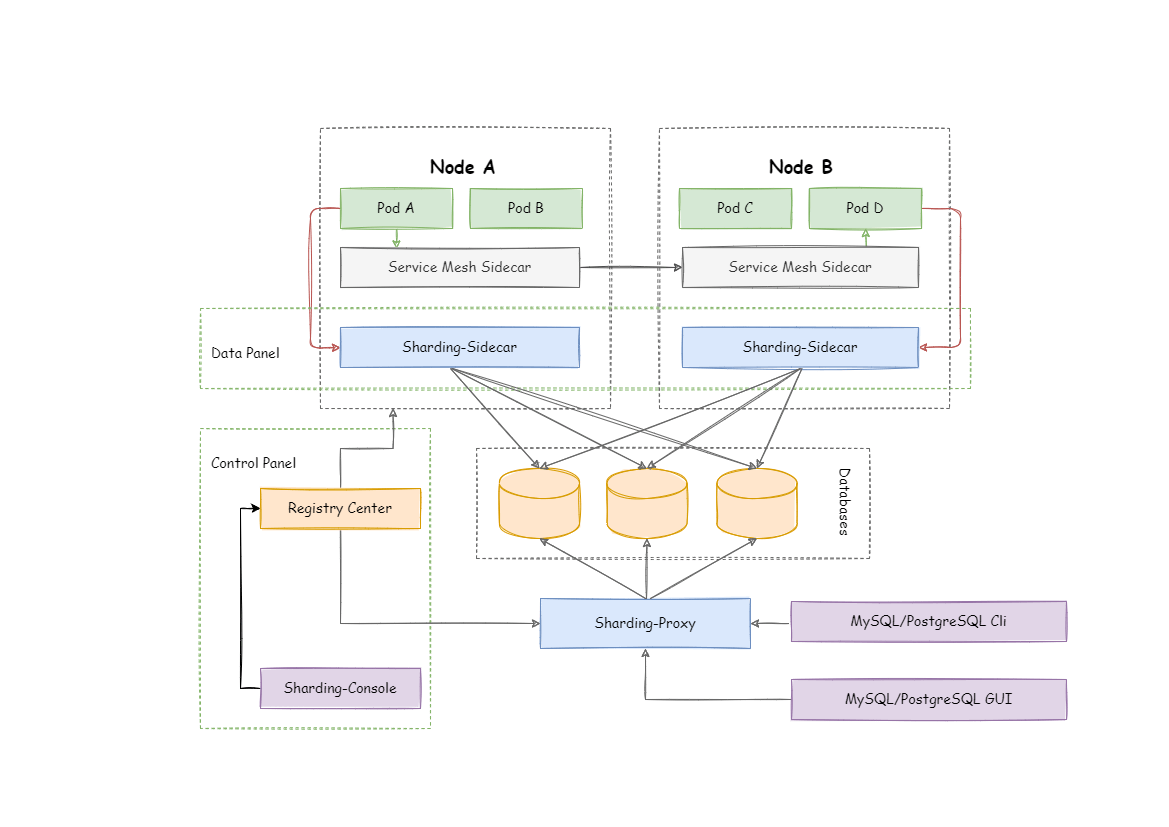
ShardingSphere-Sidecar는 본인을 Kubernetes 환경의 클라우드 네이티브 데이터베이스 에이전트로 정의한다.
SideCar 형태로 모든 데이터베이스 액세스를 담당하고, 데이터베이스와 상호작용하는 mesh layer를 제공한다. 이런 Database Mesh는 분산된 데이터 액세스 애플리케이션을 데이터 베이스와 연결하는 방법을 알려준다.
복잡한 애플리케이션과 데이터베이스간의 상호 작용을 구성한다. 데이터 메쉬를 통해서 애플리케이션과 데이터베이스는 대규모 그리드 시스템을 형성하기 때문에 적절한 위치에 배치하기만 하면 mesh layer에 의해 알아서 제어가 된다.
선택은?
| - | ShardingSphere-JDBC | ShardingSphere-Proxy |
|---|---|---|
| 데이터베이스 | Any | MySQL / PostgreSQL |
| 접속 개수 비용 | 많음 | 적음 |
| 지원되는 언어 | Java만 | Any |
| 성능 | 손실이 적음 | 비교적 손실이 높음 |
| 분산화 | 가능 | 불가 |
| 스태틱 엔트리 | 불가 | 가능 |
현재 우리는 Spring을 사용하고 있으니, 간단한 프레임워크 방식인 ShardingSphere-JDBC 방식을 사용한다.
샤딩스피어의 샤딩 알고리즘
샤딩을 하기 위한 필수 조건은 샤딩을 하기 위한 기준 키가 필요하다. 대부분 PK를 사용한다.
데이터를 분산하기 위한 샤딩 알고리즘의 종류는 여러가지가 있지만, 현재 샤딩스피어에서 지원하는 샤딩 알고리즘의 종류는 다음과 같다.
- MOD 샤딩 알고리즘
- 특정 샤드키를 모듈러 연산을 통해 나온 나머지 값을 인덱스로 사용하여 샤딩
- Volume Based Range 샤딩 알고리즘
- 데이터의 용량에 기반하여 용량에 따른 샤딩
- Boundary Based Range 샤딩 알고리즘
- 데이터의 샤드키 범위에 따라 샤딩
- Auto Interval 샤딩 알고리즘
- 일정 시간에 따라서 샤딩
- Inline 샤딩 알고리즘
- 사용자의 커스텀 알고리즘을 통해 샤딩
우리는 이 중에서 제일 많이 사용되는 MOD 샤딩 알고리즘을 사용할 것이다.
샤딩스피어의 키 생성 알고리즘
샤딩을 하기 위해 샤드키를 필요로 하는데, 특정 컬럼을 기반으로 샤드키를 생성하는 알고리즘을 정의한다.
샤딩스피어는 따로 기재하지않으면 default 값으로 snowflake 라는 알고리즘을 사용한다.
- Snowflake 키 생성 알고리즘
- Twitter가 OSS로 공개하고 있는 ID 생성 방식이다.
- 64bit 데이터로 ID를 표현하며, 시간을 베이스로 하고 있다.
- 복수의 머신에서 병렬로 동작시켜도 유일한 ID를 생성할 수 있지만, OS마다의 시각 차이에 약하다.
- 스칼라 언어로 구현되어 있다.
- UUID 키 생성 알고리즘
- 128bit 데이터로 ID를 표현한다.
- 복수의 머신에서 병렬로 동작시켜도 유일한 ID를 생성할 수 있지만, 128bit를 가지고 있는만큼 크기가 너무 크다.
샤딩스피어의 매력
샤딩스피어는 DB만 잘 구축해두면 데이터를 가져오는 방식을 우리가 신경쓰지 않고 샤딩스피어가 알아서 처리해준다는 것이다. 즉, 아주 편리하다.
기존의 샤딩 방식

기존 샤딩 데이터를 가져오게 된다면 DB마다 각각의 Datasource를 써야하고, 각 Datasource를 통해 가져온 데이터를 코드상에서 합쳐주는 방식을 사용했어야한다.
샤딩스피어를 사용한다면?

샤딩스피어를 사용한다면 하나의 데이터소스로도 여러 디비에 걸쳐 샤딩되어 있던 데이터들도 데이터를 합쳐 가져올 수 있다. (내부적으로는 datasource가 여러개지만.. 표면적으론 한개이니 한개로 설명한다.)
그래서

즉, 샤딩스피어는 다음과 같이 데이터를 들고오게 해준다.
그리고 DB단위로 샤딩을 하던, 테이블 단위로 샤딩을 하던 큰 문제없이 데이터를 CRUD 할 수 있다는 점이다.
이렇게 편하게 샤딩된 데이터를 이용할 수 있다는 것이 샤딩 스피어의 매력이다!
다음편은

이번 편은 전체적으로 샤딩과 샤딩스피어를 이해하는 시간을 가졌다.
다음편은 이제 스프링을 통해 직접 샤딩스피어를 사용하도록 하겠다!
참고
分库分表利器之 Sharding Sphere(深度好文,看过的人都说好)
A Holistic Pluggable Platform for Data Sharding — ICDE 2022 & Understanding
